
下一代芯片:加速汽车系统中的AI
人工智能计 算的助推器
实现自动和自主驾驶功能离不开人工智能。其中所需的计算能力,可由专门从事并行计算的专用芯片提供。但是,研究人员还在研究受生物启发的新型解决方案以及量子计算机,它们有望提供更高的计算能力。
近几十年来,越来越多的电子设备进入汽车。如今,数十个联网控制单元已控制了发动机、变速箱、信息娱乐系统以及其他众多功能,汽车也早已成为“带轮子的计算中心”。现在,汽车又即将在计算能力方面实现新的飞跃,因为自动和自主驾驶功能需要性能更强大的计算机。随着传统芯片逐渐无法达到必需的性能,图形处理器、张量处理器(TPU)以及其他专门为神经网络计算而设计的硬件兴起。
传统 CPU(中央处理器)尽管应用范围极广,但它们的架构并非最佳适用于人工智能。这是因为神经网络训练和推断(推理)时所进行典型计算的性质不同。“神经网络中的矩阵乘法单元构造十分繁复。”卡尔斯鲁厄理工学院(KIT)施泰因布赫计算中心(Steinbuch Centre for Computing)的马库斯·格茨博士(Dr. Markus Gotz)解释说,“但是其计算可以很好地并行化——特别是利用显卡。一个 24核高端向量 CPU 每个周期可以完成 24 次计算,而一个最先进的显卡则可超过 5,000 次。”

一尊智能的雕塑:这就是 IBM 量子计算机“Q System One”的内部构造。
图形处理器(GPU,Graphic Processing Unit)从一开始就专门用于并行工作,内部架构也是为此量身定制的:GPU 内有数百或数千个用于整数和浮点运算的简单计算核心,它们可将相同的运算同时应用于不同的数据(单指令多数据)。因此,它们能够在每个时钟周期内执行数千次算术运算——例如用于计算一幅虚拟地景的像素或执行神经网络的矩阵乘法运算符。因此,GPU 制造商 NVIDIA 的芯片目前成为一般人工智能和自主驾驶的主力军而大行其道,也就不足为奇了。这家美国公司硬件的主要用户之一是大众汽车公司。“实现自主驾驶需要专用的硬件。”保时捷工程集团软件开发负责人拉尔夫·鲍尔(Ralf Bauer)表示,“GPU 是一个开端,接下来很可能还会有专用芯片问世。”
目前,NVIDIA 提供的是专用于自主驾驶的 Xavier处理器。该产品基于一个硅芯片,上面有八个传统CPU 和一个针对机器学习专门进行了优化的 GPU。针对 2+ 级自动驾驶(有限的加减速和转向控制,相对于 2 级自动驾驶,具有基于标准传感器的扩展功能性),Drive AGX Xavier 平台每秒钟最多可执行 30 万亿次算术运算(30 TOPS,Tera Operations Per Second,每秒万亿次运算)。针对高度自动和自主驾驶,NVIDIA 拥有人工智能计算机 Drive AGX Pegasus(320 TOPS)。在其控制下的测试车辆已在硅谷完成了 80 公里的无人工干预行驶。作为 Xavier的后继产品,NVIDIA 目前正在研发 GPU Orin,关于其性能数据至今已知信息不多。
5,000
但是,并非所有汽车制造商都选用GPU。2016年,特斯拉(Tesla)开始研发自己的神经网络处理器。自 2019 年春季以来,这家美国公司便开始在其车辆上配备自主研发的 FSD(Full Self Driving,全自动驾驶)芯片,而非 NVIDIA 的图形处理器。该芯片包含两个“神经处理器”(NPU),运算能力均为72 TOPS,还有十二个传统 CPU 核心用于执行一般计算,以及一个 GPU 用于图像和视频数据后处理。与 GPU 类似,NPU 专门用于并行运算,因此可以快速执行加法和乘法运算。
适用于人工智能应用的谷歌芯片
谷歌是芯片业务的另一支新势力:自 2015 年起,这家科技公司即在其计算中心内使用自行研发的 TPU。其名称源自数学术语“张量”(tensor),其中包括矢量和矩阵。因此,谷歌为各方广泛应用的人工智能软件库也叫做“TensorFlow”——其中的芯片也经过了优化。谷歌于 2018 年推出了第三代TPU,其中包含四个“矩阵乘法单元”,运算能力总计 90 TFLOPS(Tera Floating Point Operations,每秒万亿次浮点运算)。谷歌子公司 Waymo 正在使用TPU 训练用于自主驾驶的神经网络。
“实现自主驾驶需要专用的硬件。GPU 是一个开端,接下来很可能还会有专用芯片问世。”
拉尔夫·鲍尔
软件开发负责人
特斯拉 FSD 或谷歌 TPU 之类的专用芯片只有在大量使用的情况下才较为经济。一种替代方案是FPGA(Field Programmable Gate Arrays,现场可编程逻辑门阵列):此类数字芯片具有高度通用性,其中包含大量的计算块和存储块,它们可以通过编程相互组合,从而用于将算法“浇铸”到硬件中——类似于专用芯片,但成本要低得多。因此,FPGA 可轻松适应各种人工智能应用的具体要求(例如指定的文件类型),实现更佳的性能和能耗。慕尼黑初创公司 Kortiq 针对 FPGA 开发出“AIScale”架构。它可简化神经网络图像识别并优化计算,从而使硬件需求显著降低,生成结果的速度却可加快最多十倍。
一些研究人员致力于使人工智能专用芯片更加近似地仿照神经细胞的工作方式。海德堡大学构建了神经形态系统“BrainScaleS”,其人工神经元采用硅芯片模拟电路形式:胞体由大约 1,000 个晶体管和两个电容器构成,突触大约需要 150 个晶体管。各个胞体可以如同积木一样,组合成不同类型的人工神经元。如同在自然界中一样,突触可以建立不同强度的连接,而且还分为兴奋型和抑制型。神经元的输出由一个个“峰值”构成——它们是持续时间为几微秒的短暂电压脉冲,可作为其他人工神经元的输入。

自主驾驶平台:NVIDIA Drive AGX Pegasus 人工智能高性能计算机专用于研究深度神经网络。
节能神经芯片
BrainScaleS 不单可用于研究人类的大脑,借助这种人工神经元,还可以解决种种技术问题,例如自主驾驶中的对象识别。因为它们一方面可凭借每个模块 200,000 个神经元的配置,提供每秒钟高达约一千万亿次运算(1,000 TOPS)的计算能力。另一方面,模拟式解决方案能耗又极低。“例如在数字电路中,每次运算大约会用到 10,000 个晶体管。”海德堡大学的约翰内斯·谢梅尔(Johannes Schemmel)解释说,“我们可以凭借少得多的资源实现目标,达到约每瓦特 100 TOPS 的能效。”研究人员最近刚刚开发出第二代电路,并正在与工业合作伙伴洽谈合作意向。
量子能力,来自云端
将来,量子计算机可能也可应用于人工智能领域。它的基本单位不是二进制位,而是具有无限多个可能值的量子位。凭借量子力学定律,计算可以大程度并行化,从而加快速度。但是,量子计算机很难实现,因为量子位必须由敏感的物理系统(例如电子、光子或离子)表示。一个例子便是 IBM 公司在拉斯维加斯 CES 2019 国际消费电子展上展出的“IBM Q System One”:量子计算机的内部必须完全屏蔽振动、电场和温度波动。
这款 IBM 计算机并无市售,但可以通过云来使用。其他一些制造商,比如加拿大的 D-Wave 公司也提供量子计算能力。作为范例,大众汽车目前就使用该公司的一台量子计算机实现了一套交通管理系统,可改善出租汽车公司及其他城市公共交通服务商的效率。“神经网络同时也是一项优化任务——通常,人们希望获得最佳的预测准确度。”KIT 专家格茨指出,“因此,目前的主要研究方向是如何修改应用于量子计算机的人工智能算法。”

诞生于海德堡的神经形态硬件:这枚芯片上有 384 个人工神经元和 100,000 个突触。
神经细胞和人工神经元

神经细胞通过突触从其他神经元接收信号,突触可能位于树突上或直接位于胞体上。突触可以产生兴奋作用或者抑制作用。所有输入会在轴丘处相加,当超过阈值时,神经细胞会发出一个持续约一毫秒的信号,该信号会沿着轴突传播并到达其他神经元。

人工神经元以不同程度的准确度模仿这种行为。在传统多层神经网络中,每个“神经细胞”都会获得一个加权值并作为输入。它由上游层中神经元的输出ai和储存有神经网络学习经验的权重因子wi组成。这些权重因子对应于突触,同样可以产生兴奋作用或者抑制作用。类似于神经细胞,人工神经元何时触发由一个可调阈值决定。
神经网络的学习和推断
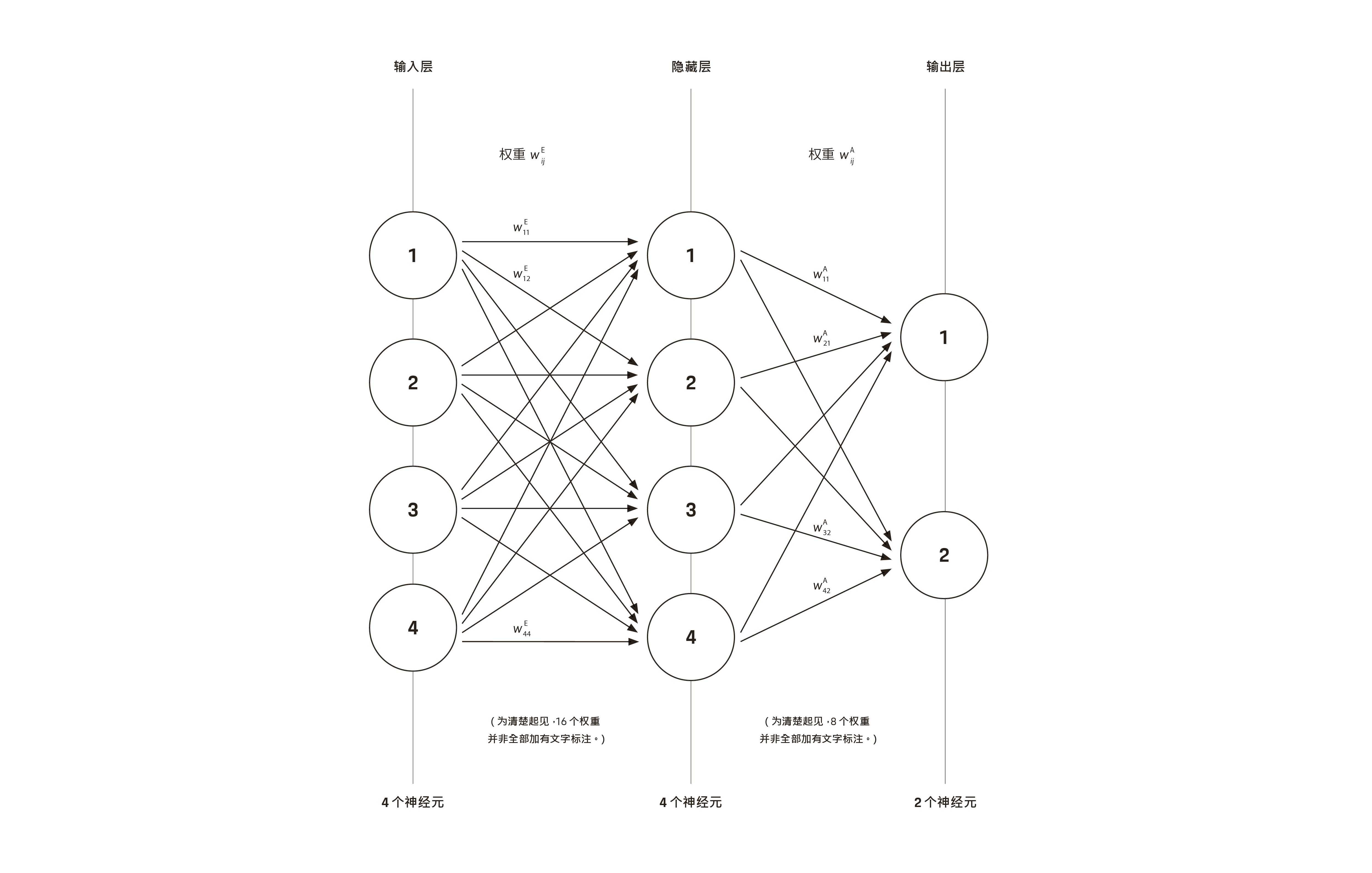
自然和人工神经网络通过改变突触连接或权重因子的强度来进行学习。在深度神经网络内,训练过程中会向其输入端输入数据,并将输出与所需结果进行比较。借助数学方法,可以不断调整权重因子wij,直到神经网络能够可靠地完成任务,例如将图片归类至指定分类。进行推断时,可向输入端输入数据并使用输出变量进行决策。
无论在深度神经网络(具有多层人工神经元的网络)学习还是推断,相同的数学运算都会一次又一次地发生。如果将第1层中神经元的输出和第 2层中神经元的输入分别组合为列向量,则所有计算都可以表示为矩阵乘法。其中涉及大量彼此独立的乘法和加法运算,它们可以并行执行。传统CPU 并非为此而设计,因此表现不如图形处理器、TPU及其他人工智能加速器出色。
综述
对于神经网络计算,传统计算机芯片已经达到极限。由NVIDIA 和谷歌等公司开发的图形处理器和专用人工智能硬件性能要强大得多。神经形态芯片在很大程度上基于真实的神经元,并且非常节能。量子计算机可以进一步显著提高计算能力。
信息
本文首次发表于《保时捷工程杂志》2019年第2期。
文字:Christian Buck
共同撰稿:Ralf Bauer、Christian Koelen 博士
版权:本文中发布的所有图片、视频和音频文件均版权保护。未经保时捷工程书面许可,不得部分或全部复制。欲了解更多信息,请联系我们。
联系方式
您有问题或想了解更多信息吗?请联系我们:info@porsche-engineering.de