
借助 Delta Learning 实现更智能的车辆 AI 再训练
差之毫厘, 谬以千里
对汽车自动驾驶系统来说,驾驶环境情况的变化从来都是一项极大的挑战。目前,如果交通标志或规则发生些微变化,系统就必须重新接受训练,从头学起。由德国联邦经济和技术部资助的研究项目“人工智能德尔塔学习”(KI Delta Learning)旨在解决这一问题,从而大大减少自动驾驶系统训练工作量。
许多国家的停车标志看起来都差不多— —红色、八角形,中间有一个“STOP”(停)字样。然而,也有不少例外。在日本,停车标志是三角形的;在中国,“STOP”这个词被一个“停”字取代;而在阿尔及利亚,标志中间则是一只举起的手。对于外地来的司机,这些细微差别并不会产生多大问题。只要稍微开一段路,他们就能清楚明白当地的停车标志是什么样子。但是,对于自动驾驶汽车中的人工智能来说,要处理这种微小的差异,就需要一个全新的训练过程。
这些变化使得人工智能的训练不得不消耗大量时间,并产生高额费用,从而阻遏了自动驾驶系统的发展。出于这个原因,汽车行业的各大巨头现在决定联手合作,通过“人工智能德尔塔学习”项目寻找解决办法,让自动驾驶汽车人工智能系统的学习变成一种有选择性的、针对新事物的学习。我们继续看停车标志这个例子。在未来,如果这个项目成功达成目标,那么你需要做的就是告诉汽车自动驾驶系统:“只需要学习新的停车标志,其他的照旧不变。”

“项目的目标是要降低 人工智能系统从一种驾 驶情况自行推导出 另一种情况的难度, 以避免额外的训练。”
约阿希姆·舍珀博士
保时捷工程公司人工智能和大数据主管
这是一个具有重大意义的项目,不仅得到了德国联邦经济和技术部的资助,项目参与者也都是赫赫有名的汽车巨头以及高校:除了保时捷工程公司外,该项目的合作伙伴还包括宝马、CARIAD 和奔驰,以及博世等大型供应商,另外还有九所大学,其中包括慕尼黑工业大学和斯图加特大学。“项目的目标是要降低人工智能系统从一种驾驶情况自行推导出另一种情况的难度,以避免额外的训练。”保时捷工程公司人工智能和大数据主管约阿希姆·舍珀(Dr. Joachim Schaper)博士解释说,“携手合作是非常有必要的,因为目前没有任何一个厂商能单独解决这一挑战。”该项目是“人工智能家族”项目(KI Familie)的一部分,这是德国汽车工业协会旨在推进互联和自动驾驶的旗舰计划。
从 2020 年 1 月开始,来自共 18 个合作企业及高校的约 100 人一直在研究“人工智能德尔塔学习”这一项目。专家们举办了多次研讨会,共同讨论各种方案的可能性,彼此交换意见。梅赛德斯-奔驰的自动驾驶专家兼项目负责人莫森·塞法提(Mohsen Sefati)说:“最终,我们希望能为厂商提供一份有关人工智能知识转移方法的清单。”
事实上,停车标志这个例子很好地展现了自动驾驶领域所使用的神经网络系统的一个基本弱点。这些神经网络系统结构与人脑相似,但在一些关键方面有所不同:神经网络只能进行一次性学习,且通常是通过一次大型训练,方能习得某些知识。
70,000
100
50
%
“领域变化”带来的极大训练工作量
即使是道路交通上微不足道的变化,也会给自动驾驶系统的训练带来极大的工作量。举一个例子:目前,在许多自动驾驶的测试车辆中,已安装了分辨率为 200 万像素的摄像头。如果现在改装为分辨率更高的 800 万像素摄像头,原则上其实几乎没有任何变化。在摄像头里,一棵树看起来仍然是一棵树,只是在图像中以更多的像素表现出来。但此时,人工智能就需要再次从实际交通状况中获取数以百万计的快照,才能在更高分辨率的情况下识别同一物体。如果车辆上的摄像头或雷达传感器的位置略有不同,人工智能也同样需要再次花费大量的时间精力进行训练,方能习惯这一变化。这就意味着,训练需完全重头开始。
专家们把这样的变化称为“领域变化”。当人们不再靠右行驶,而是靠左行驶,或者当道路上不再艳阳高照,而是风雪肆虐时,人类驾驶员通常能轻易地适应这些变化。他们凭直觉就能察觉到是什么在变化,并将他们已有的知识转移并应用到新的情况当中。但神经网络系统还不能做到这一点。例如,一个在良好天气条件下经过驾驶训练的系统,在雨中就会“手足无措”,因为它此时无法再能识别这一新的环境。同样,如果出现了其他新的天气条件,或者从靠左行驶变成了靠右行驶这样的交通变化,或者出现不同类型的交通灯,神经网络系统同样无法适应。另外,如果交通中出现了全新的物体,比如电动滑板车,那么自动驾驶系统也必须从头学习这些新事物。
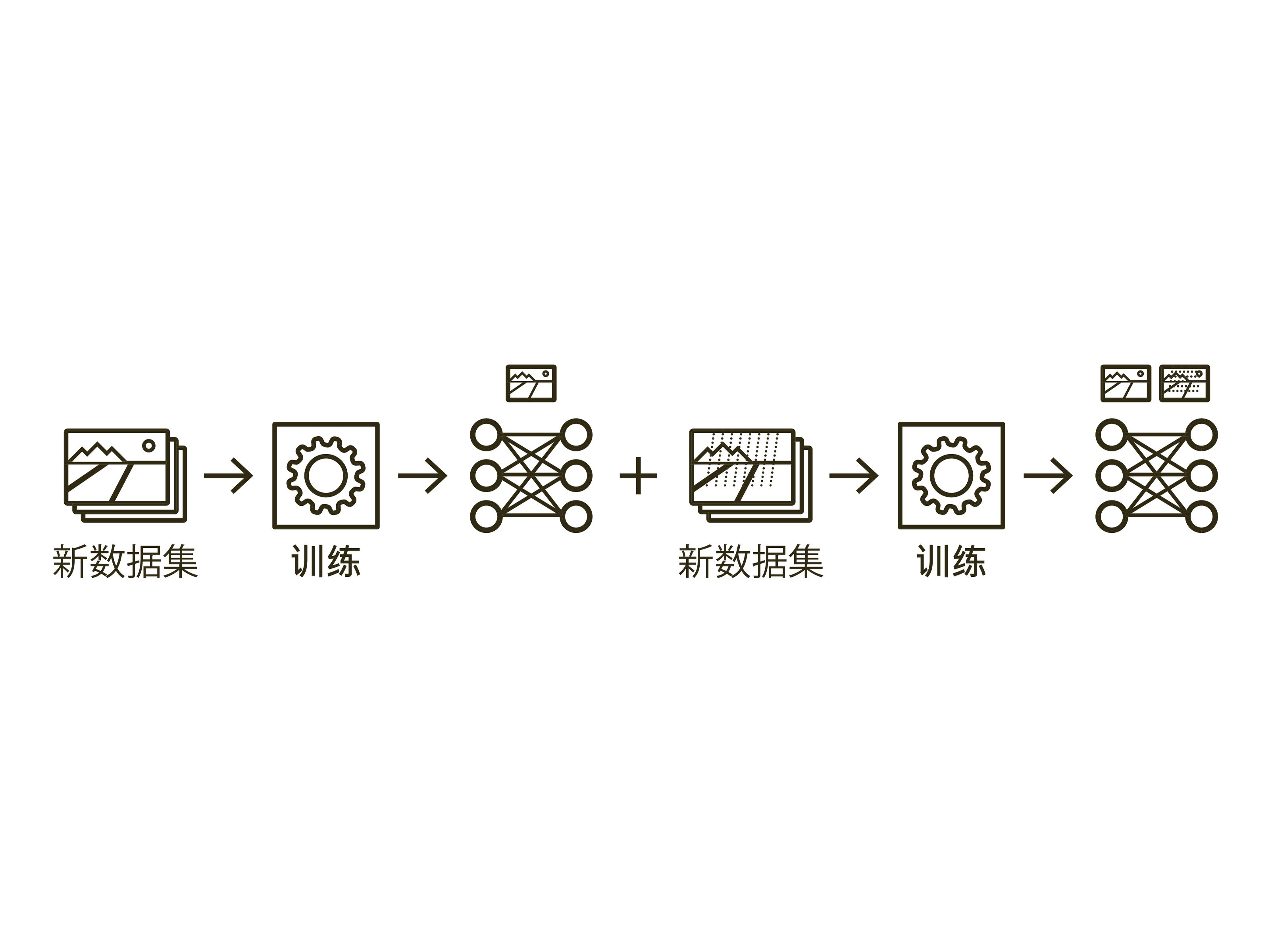
持续学习
持续学习这种学习模式,能让人工智能一步步地将新知识添加到神经网络中。这样,它们也能将已学到的知识保留在“记忆”中,而不必每次都用完整的数据集从头开始再次进行训练。
初次训练

(1) 神经网络系统学会分辨形状。

(2) 神经网络系统学会正确将颜色分类。

(3) 神经网络系统学会区分不同的标志和标语。

(4) 具备上述能力后,现在就可以识别德国的停车标志了。

学习更多的知识
基于之前学到的有关德国交通标志形状、颜色和标语的知识,神经网络系统此时只需要通过德尔塔学习方法学习新的标语,然后就能准确识别日本的停车标志了。
项目目标:让人工智能只学习“德尔塔”
目前在上述所有情况中,算法仍然无法只学习新的变化,这些新变化被科学家称为“德尔塔”(Delta)。为了适应新的领域,人工智能就需要一个完整的、包含些许变化调整的新数据集。就好像一个学生,每学习一个新的词汇,都需要将整本字典再从头到尾翻阅一遍一样。
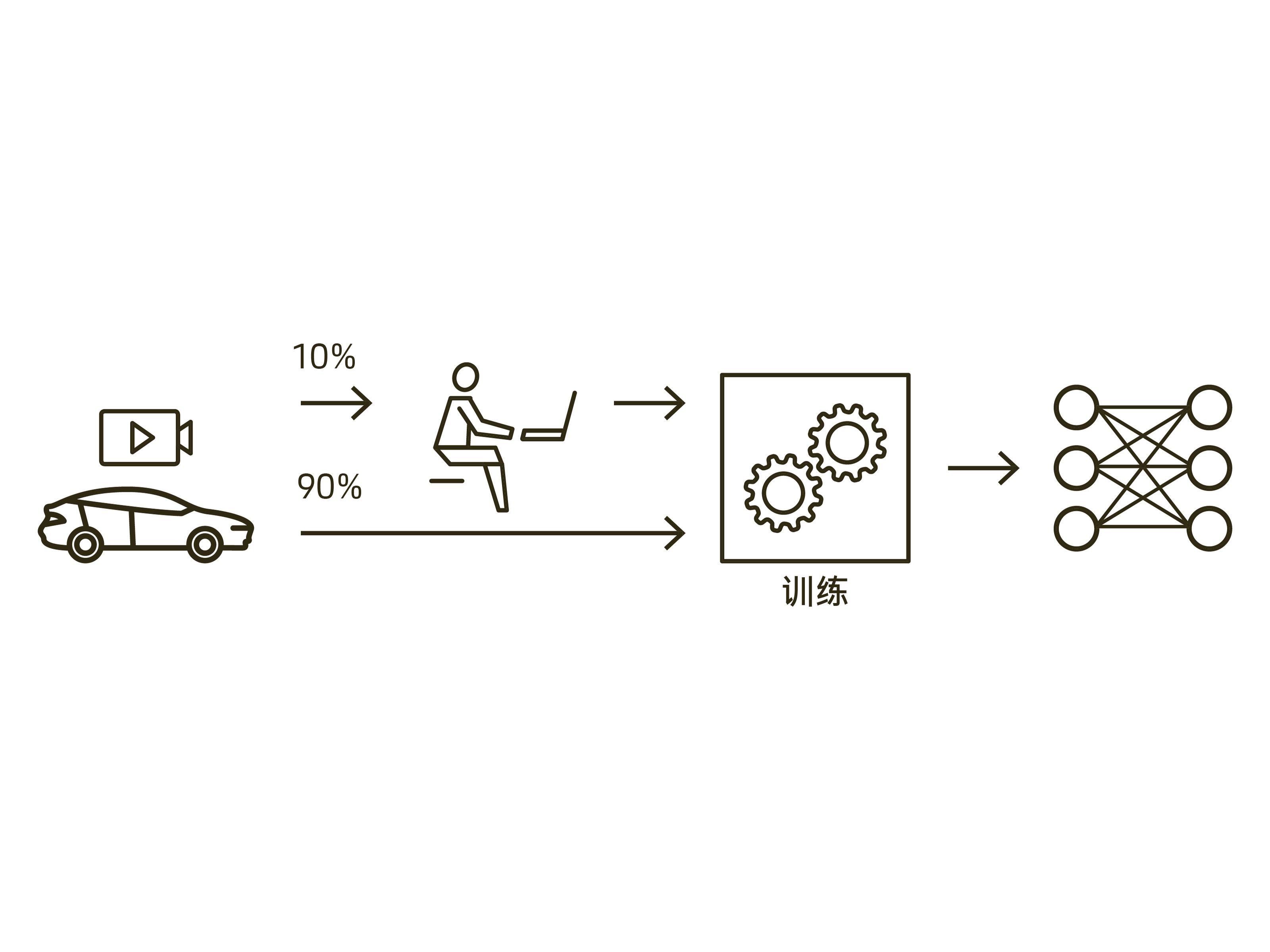
这种学习模式需要耗费许多资源。“目前,训练一套自动驾驶系统需要 7 万个小时(GPU 时长)。”参与保时捷工程公司“人工智能德尔塔学习”项目的博士生托比亚斯·卡尔布(Tobias Kalb)补充说。在实际操作中,尽管研究人员会同时使用多个图形处理器(GPU)来训练神经网络系统,但其工作量仍然十分巨大。此外,神经网络系统需要的是带标注的图像,这些图像来自真实的交通状况,并且其中的重要元素已被一一标出,比如其他车辆、车道标志或障碍物等。如果人工手动操作完成这项标记工作,仅仅是一张交通快照就需要一个小时或更长时间来进行注解。每一个行人、每一条斑马线、每一个建筑工地的圆锥形路障都必须在图中标记出来。这种标记工作可以实现部分自动化,但仍需要占用大量的算力。

两种不同的“停”:不同国家的道路标记不一致,比如英国(左)和韩国的“停”标志,大大提高了目前人工智能系统的训练难度。
此外,当一个神经网络系统适应一个新的领域时,有时就会忘记它之前所学到过的东西。“它没有一个真正意义上的记忆。”卡尔布解释说。他自己在使用美国交通场景训练人工智能系统时,就遇到过类似的情况。人工智能系统在经过大量空旷路面和地平线照片的训练后,已经可以准确地识别天空。当卡尔布再用德国的数据集来训练该系统时,就出现了问题。第二次训练运行完毕后,神经网络系统就再也无法在美国的照片中准确地识别天空。因为在德国的照片中,天空常常阴云密布,或者干脆被建筑物遮挡。
“目前,如果遇到这种情况,我们就需要用两个数据集来重新训练系统。”卡尔布补充说。但这很耗时,而且在某些时候根本无法操作,例如当数据集非常庞大,无法保存时。卡尔布自己通过实验找到了一个更好的解决方案。“有时,一些非常有代表性的图片就足以让系统‘回忆’起过去已经学习过的知识。”例如,他不再向系统展示所有美国和德国道路的照片,而是选择了几十张具有代表性的长途公路景观照片。这就足以提醒算法,天空到底长什么样子。
“人工智能家族”项目

人工智能知识
致力于研发将知识纳入机器学习的方案。

人工智能德尔塔学习
致力于扩展和改造现有自动驾驶车辆的人工智能模型,以应对新领域或更复杂场景的挑战。

人工智能保障
致力于确保自动驾驶中人工智能感知功能的正常运作。

人工智能数据工具
致力于高效、系统地研发和完善有关人工智能训练、测试、验证和保障数据的过程、方法和工具。
两个人工智能相互训练
专家们希望通过“人工智能德尔塔学习”这一项目,寻找这样类似的优化可能性。针对六个不同的应用领域,参与项目的专家们正在寻求人工智能快速且简单的训练方法。这样,能让人工智能更快地适应比如传感器的变化或新的天气条件。解决方案在参与项目的各个组织之间得到验证并相互共享。
除了上述可能性外,目前还有一个非常有希望的解决方案,就是让两个感知型人工智能互相训练。首先,需要为此建立一个“教师”模型。由这个模型接收训练数据,在这些数据当中,某一类对象已做好标记,例如交通标志。第二个人工智能,即“学生”模型,也获得一个数据集,但数据集中被标记的则是其他不同的对象,比如树木、车辆、道路等。然后,“教学”就开始了。当“学生”模型学习新概念时,“教师”模型负责将知识传授给“学生”。这样,学生就可以识别交通标志。接下来,“学生”反过来成为“老师”,对另一个系统进行教导。这种方法被称为“知识蒸馏(Knowledge Distillation),可以帮助原始设备制造商节省大量车辆本地化的时间。此时,如果制造商要在一个新的市场中推出一个新的自动驾驶模型,那么他们在训练自动驾驶系统时,就只需要针对比如该地区的交通标志,使用一个与之前不同的“教师”模型即可,其他的都可以保持不变。
当然,到目前为止,研究人员测试的大部分内容仍然停留在实验阶段。现在我们还不能预知,到底哪种方法最终会成为让神经网络系统适应新领域的最佳方案。“最终解决方案将会是多个方案的巧妙结合。”卡尔布设想道。经过一年的项目工作之后,所有参与者均表示乐观。“我们已经取得了良好的进展。”梅赛德斯-奔驰项目经理塞法提说。他预计在 2022年底项目结束时,就已经能提出“人工智能德尔塔学习项目”第一批成熟的解决方案。这将为整个汽车行业带来巨大的收益。“如果训练过程实现高度自动化,那么训练就能在提高质量的同时,实现高度节约。”人工智能专家舍珀解释说。他预计,通过“人工智能德尔塔学习”,自动驾驶汽车研发工作所需的工作量投入将可减少一半。
人工智能德尔塔学习的五种方法
(1) 持续学习
持续学习需要一种能在不产生知识折损的情况下扩展新知识的算法,而不是使用整个数据集重新进行训练。与传统方法不同的是,持续学习并不需要所有数据都到位。相反,其他数据可以在日后的训练中逐渐加入。例如,一个神经网络系统可以在学习识别日本的停车标志的同时,不忘记德国的停车标志。
(2) 半监督学习
如果采用的是“半监督学习”方式,就只需要在一小部分数据上添加分类标记即可。此时,算法使用无标记和有标记的数据进行训练。这样,就能利用已使用标记数据完成训练的模型,来预测一部分未标记的数据。然后,这些预测可以被纳入训练数据当中,作为一个扩展了的数据集来训练另一个算法模型。
(3) 无监督学习
如果采用“无监督学习”的方式,人工智能则使用事先未手动标记分类的数据进行学习。这样,算法就会对数据进行聚类、从中提取特征,或在没有人类协助的情况下学习输入数据的新的压缩表示方式。在“人工智能德尔塔学习”项目中,无监督学习一方面被用来初始化神经网络系统,减少注解训练数据的数量;另一方面,它可以让系统通过尝试学习数据的统一表现方式,来使已训练好的神经网络系统适应一个新的领域。例如,当领域从白天变化到夜间时,模型在白天学习的特征应该同样在夜间适用。因此,在理想情况下,这些特征应当属于恒定领域。
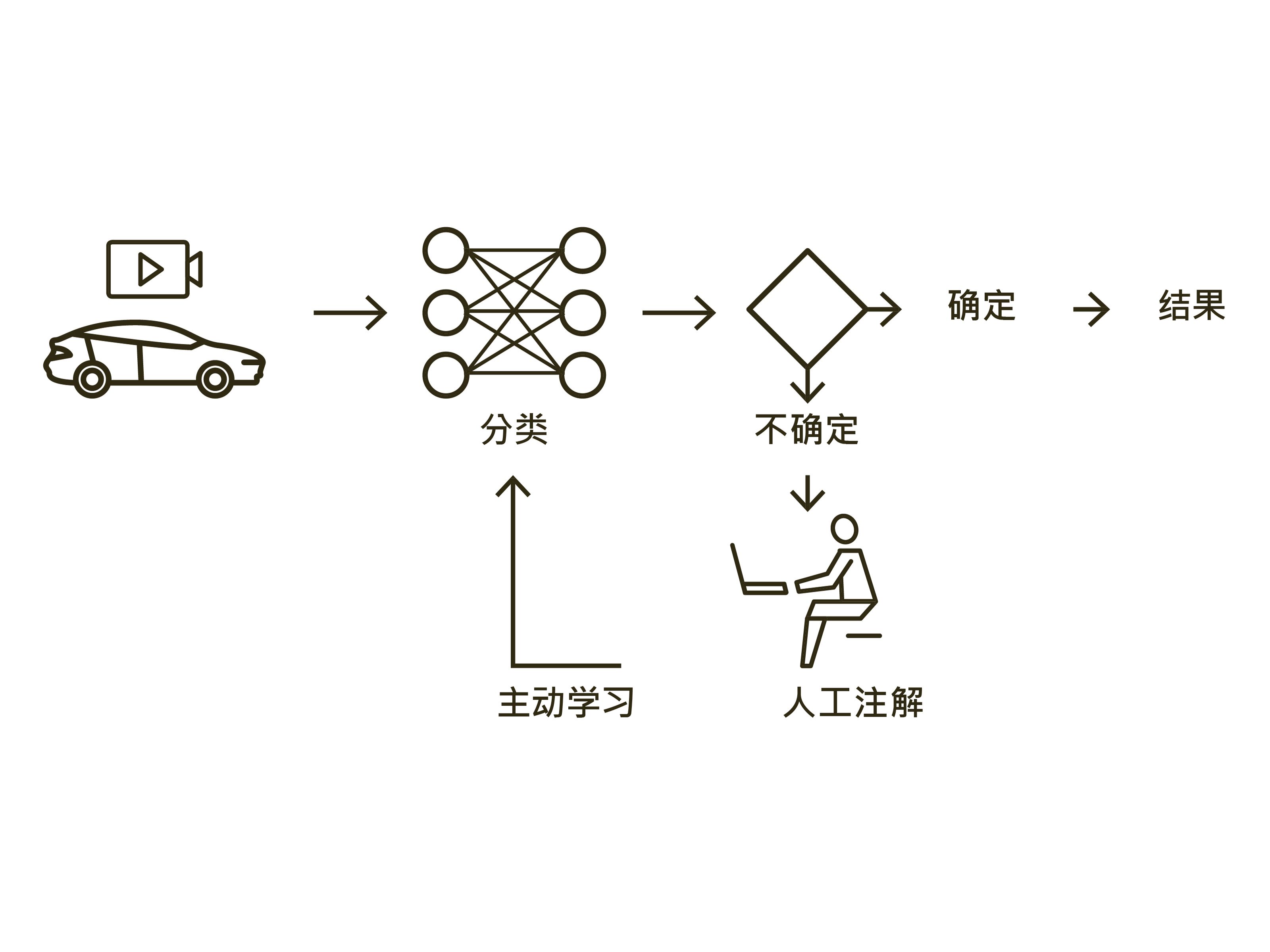
(4) 主动学习
如果采用“主动学习”这一方式,神经网络算法就会在训练期间自行挑选训练数据,比如专挑那些以前没有发生过的新状况。其挑选的依据是不确定程度,也就是神经网络系统在对这些情况展开预测时,其不确定程度有多高。这样的话,“主动学习”可以大大减少手动注解视频图像的工作量,因为此时人只需要处理那些后来对学习至关重要的训练数据即可。
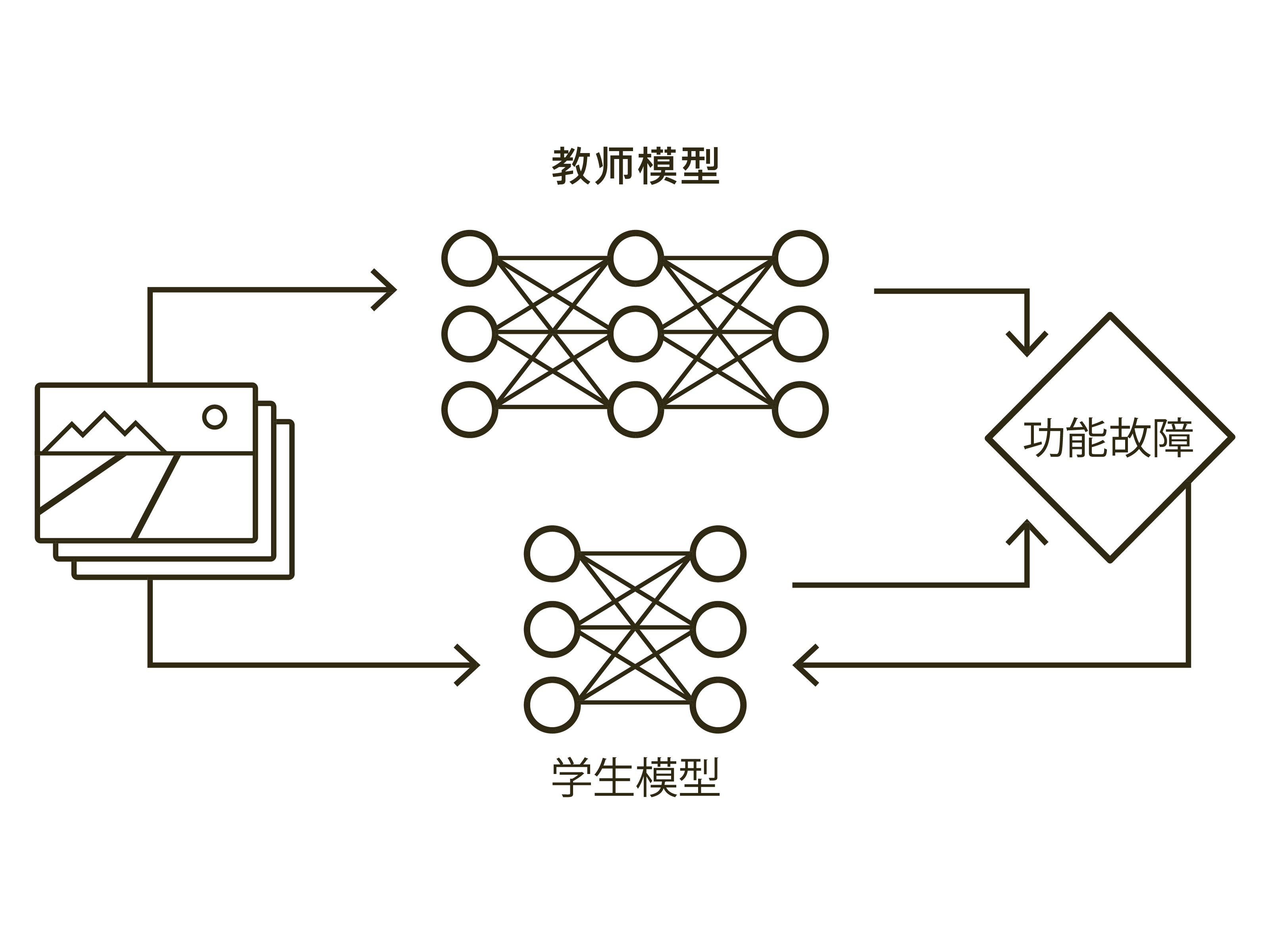
(5) 知识转移
知识蒸馏是指在神经网络系统之间进行知识转移,通常是把知识从一个更复杂的模型(教师)转移到一个更简单、更小的模型(学生)。更复杂的模型通常具有更大的知识容量,从而可达到更高的预测精度。知识蒸馏将复杂网络中包含的知识压缩到一个较小的网络当中,且几乎不产生准确性折损。知识蒸馏也可用于持续学习,以减少神经网络系统在学习过程中的知识流失。
综述
目前,当环境或传感器发生些微变化时,自动驾驶车辆中的神经网络系统就必须从头开始重新训练一遍。而“人工智能德尔塔学习”项目的目标正是要教会人工智能只需学习领域变化后的新内容即可,从而大大减少训练工作量。
信息
本文首次发表于《保时捷工程杂志》2021年第2期。
文字:Constantin Gillies
版权:本文中发布的所有图片、视频和音频文件均版权保护。未经保时捷工程书面许可,不得部分或全部复制。欲了解更多信息,请联系我们。
联系方式
您有问题或想了解更多信息吗?请联系我们:info@porsche-engineering.de